Les IA échouent à 50% sur les tâches SRE : le benchmark qui dérange
Pourquoi ça compte pour toi
Si tu utilises l'IA pour automatiser ton infra ou tes ops, c'est le signal : les modèles "frontière" butent encore sur le diagnostic d'incidents critiques. ITBench-AA expose un vrai problème — les agents surenquêtent, hallucinent des causes, et mélangent symptômes avec causes réelles. C'est pas du marketing : c'est un benchmark qui refuse de saturer.
Ce qu'il faut retenir
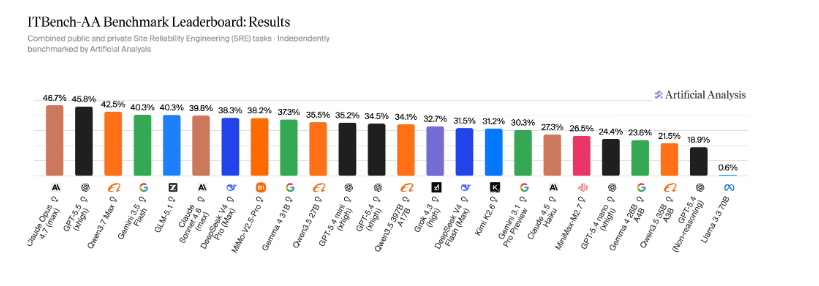
- 1.Claude Opus 4.7 en tête à 47%, GPT-5.5 à 46% — tous sous 50% sur le SRE
- 2.83 tours d'investigation ne battent pas 58 tours : plus long ≠ mieux (faux positifs en cascade)
- 3.Gemma 4 31B coûte $0.14/tâche et score 37%, vs Gemini 3.1 Pro à $2.23 et 30% — l'open-source gagne
- 4.Les modèles confondent cause racine et symptômes en amont (détectent un contrôleur chaos au lieu du vrai bug)
Tu galères avec le jargon ?
Lis la version réécrite en mode débutant — toutes les idées, sans le jargon.
Le benchmark qui ne flatte personne
ITBench-AA, c'est un projet concocté par Artificial Analysis et IBM : 59 tâches SRE réelles basées sur des incidents Kubernetes — alertes, logs, traces, topologies entières. L'agent doit identifier les entités Kubernetes responsables (Deployments, Pods, Services) sans ajouter du bruit.
Le scoring est sans pitié : tu dois trouver tous les coupables sans inventer de faux suspects. Manquer un seul ? Score 0 sur cette tentative. C'est pour ça que les modèles qui font de la surenchère exploratoire s'effondrent.
Le piège de l'investigation excessive
Gemini 3.1 Pro Preview moyenne 83 tours par tâche mais score 30%. Pourquoi ? À force de fouiller les logs, elle remonte des mécanismes d'injection de pannes (chaos-mesh) ou des symptômes cooccurrents — pas la cause réelle. Gemma 4 31B, elle, fait 58 tours à 37% de score. Moins de bruit, meilleur diagnostic.
Cette asymétrie révèle un défaut structurel des agents actuels : ils confondent corrélation et causalité dans un environnement complexe.
Le virage du coût
L'open-source commence à griffer.
GLM-5.1 (Reasoning) : 40% à $1.23/tâche. Gemini 3.5 Flash : 40% à $1.70/tâche. Claude Opus 4.7 : 47% à $5.38/tâche — en tête, mais coûteux.
Pour un ops qui tire 50 diagnostics par jour, le choix entre un modèle ouvert et Claude, c'est une question d'argent. Gemma 4 31B peut tourner en local.
À retenir
ITBench-AA refuse de saturer parce qu'il mesure quelque chose de difficile : l'IA ne peut pas remplacer un SRE humain sur des incidents critiques. Mais elle peut seconder — sauf si tu laisses l'agent explorer comme un enfant perdu dans une bibliothèque.
Et concrètement pour toi ?
Choisis ton profil — la lecture de l'article change selon qui tu es.
Pour toi, ce benchmark casse un mythe : les IA frontière galèrent encore sur des tâches concrètes et critiques. Retiens que « hallucination en cascade » signifie que l'IA confond un symptôme avec sa cause — un piège humain aussi, mais plus transparent chez nous.
Essayer maintenant
Explorer le leaderboard ITBench-AA →Source
📊 Cours en bourse
Pour aller plus loin
Cet article t'a donné envie d'approfondir ? Deux formations Noésis t'attendent :
Explorer les thèmes de cet article :