Construire petit : comment un modèle 4B a battu un 27B sur les arnaques
Pourquoi ça compte pour toi
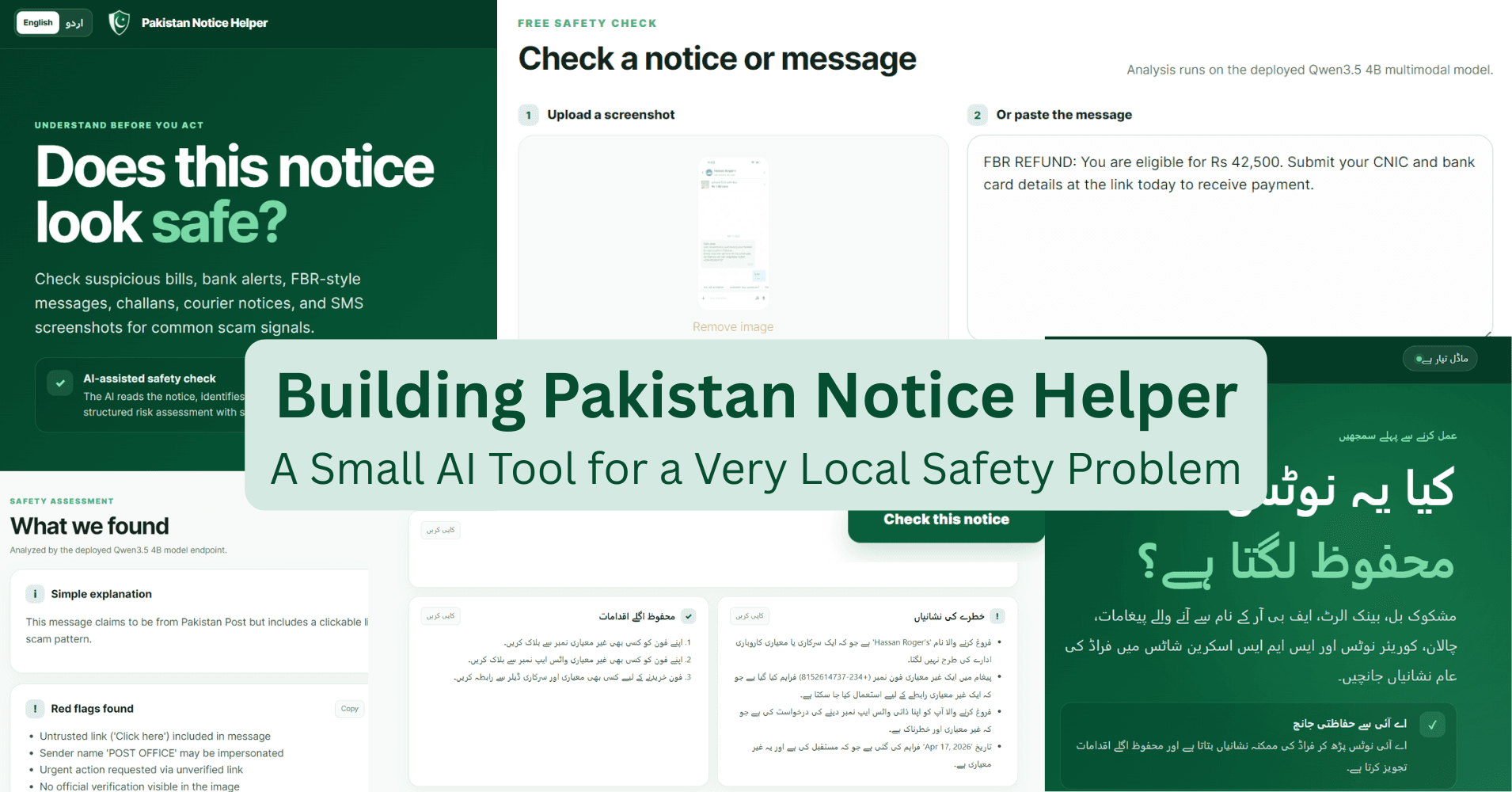
Tu crois que plus gros = mieux ? Pakistan Notice Helper raconte l'histoire inverse : un modèle de 4 milliards de paramètres qui détecte les arnaques SMS mieux qu'un 27B — pour une fraction du coût. C'est une leçon pour quiconque construit avec l'IA : ton modèle doit résoudre TON problème, pas gagner une course aux benchmarks. Et si tu opères en zone d'instabilité réseau, tu vas aimer la suite.
Ce qu'il faut retenir
- 1.Qwen 3.5 4B (via llama.cpp) détecte les faux messages bancaires pakistanais aussi bien qu'un 27B, mais 10× moins cher à déployer
- 2.Prise en charge native de l'Urdu + interface droite-à-gauche : pas juste une traduction, une refonte complète de l'interface
- 3.Trois écueils testés : les gros modèles coûtent trop en infrastructure, MiniCPM 4.6 s'écroule sur ZeroGPU, la sortie structurée doit être stricte (pas d'URLs inventées)
Tu galères avec le jargon ?
Lis la version réécrite en mode débutant — toutes les idées, sans le jargon.
Pourquoi commencer par du lourd ?
L'auteur a d'abord utilisé Qwen 3.6 27B. Résultat : 95/100 sur la détection d'arnaque. Mais voilà le hic : VRAM énorme, GPU coûteux, démarrages à froid catastrophiques. Sur une démo hackathon avec du trafic irrégulier, ça saigne en frais d'infrastructure.
Le piège du "assez petit"
Il a essayé MiniCPM-V 4.6 Q8 pour réduire les coûts. Résultat : lent sur GPU, instable sur ZeroGPU (quota qui s'écoule sans raison), et en test, le modèle ratait trop de cas. À jeter.
La formule Goldilocks
Qwen 3.5 4B. Assez petit pour respecter la limite de 32B du hackathon. Assez rapide (chargement en quelques secondes). Assez capable : 80/100 sur le même benchmark (15 points de moins que le 27B, mais sur une tâche très spécifique). Et surtout : pas cher à déployer sur une petite machine Modal.
Les détails qui tuent (ou sauvent)
Trois points non évidents :
- ▸Pensée activée = perte de tokens : désactiver le mode "thinking" pour ne pas gaspiller les 500 tokens de budget sur du calcul intermédiaire.
- ▸Langage mixte = débordement : une capture d'écran en Urdu romain a dépassé la limite. Solution : augmenter le budget pour les images.
- ▸Le modèle hallucine des URLs : la première version suggérait des domaines "officiels" qui n'existaient pas. Prompt durci : interdiction absolue d'inventer des faits, numéros, organisations.
Urdu : c'est plus qu'une traduction
Pas juste des libellés traduits. Mise en page droite-à-gauche, réponses du modèle en Urdu script clair, hauteurs de ligne ajustées pour le RTL. Et non, pas de fonte Nastaliq élaborée : elle nuisait à la lisibilité en contexte d'interface. Retour aux polices système.
À retenir
Le meilleur modèle n'est pas celui avec le plus de paramètres. C'est celui qui répond à tes contraintes (coût, latence, matériel) tout en restant assez bon pour la tâche. Pour Pakistan Notice Helper, un 4B bien ciblé valait mieux qu'un 27B qui vidait la caisse.
Et concrètement pour toi ?
Choisis ton profil — la lecture de l'article change selon qui tu es.
Pour toi, retiens que la course aux modèles géants cache une réalité : les vrais gagnants sont ceux qui adaptent des outils petits et agiles à des problèmes locaux. C'est comme comparer un truck vs une moto — tout dépend du terrain.
Essayer maintenant
Tester Pakistan Notice Helper →Source
Pour aller plus loin
Cet article t'a donné envie d'approfondir ? Deux formations Noésis t'attendent :
Explorer les thèmes de cet article :