Tag
#inference
15 articles sur ce sujet.
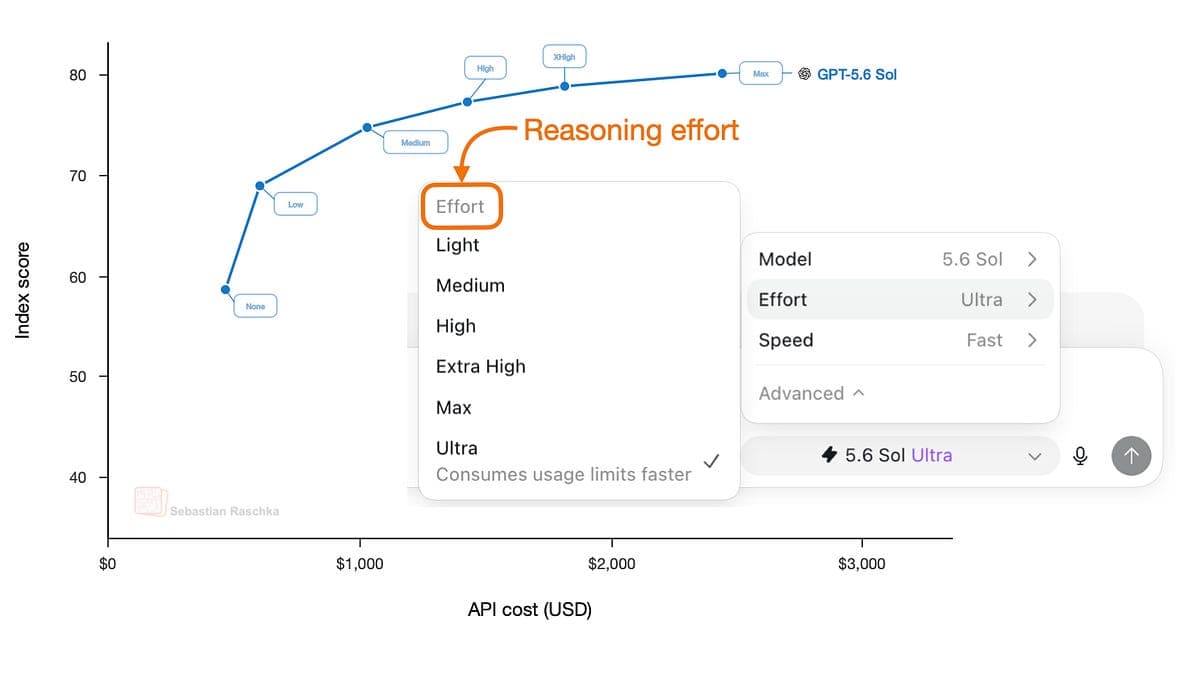
GPT-5.6 : doser l'effort de réflexion de ton IA
OpenAI te laisse enfin choisir combien de temps ton IA doit réfléchir avant de répondre.

Les GPU ne suffisent plus : le boom silencieux de l'inférence
Upper90 finance des puces d'inférence en collatéral. Le signal que l'ère des GPU monopolistiques s'ébrèche.

ZML libère un moteur d'inférence gratuit compatible tous chips
Une startup parisienne vient de casser le monopole Nvidia en créant un logiciel qui fait tourner l'IA sur n'importe quel processeur.

GPU bubbles : comment Moondream gagne 35% de débit
Ton GPU s'ennuie pendant que le CPU prépare le prochain token. Voici comment le remplir.

Pourquoi faire raisonner une IA l'aide à se souvenir
Une IA peut débloquer des connaissances qu'elle possède mais ne trouve pas — juste en réfléchissant à voix haute.

OpenAI sort Jalapeño, son premier chip maison
OpenAI fabrique sa propre puce d'inférence avec Broadcom pour réduire sa dépendance à Nvidia.

GLM-5.2 : le modèle ouvert qui change la donne
Un modèle chinois ouvert vient de franchir un seuil qui redéfinit ce qu'on peut faire sans API propriétaire.

Quatre petits modèles, une économie vivante : le vrai défi de l'IA
Quand tu fais fonctionner des agents IA sur quatre modèles différents, la vraie friction n'est pas la puissance : c'est la plomberie.
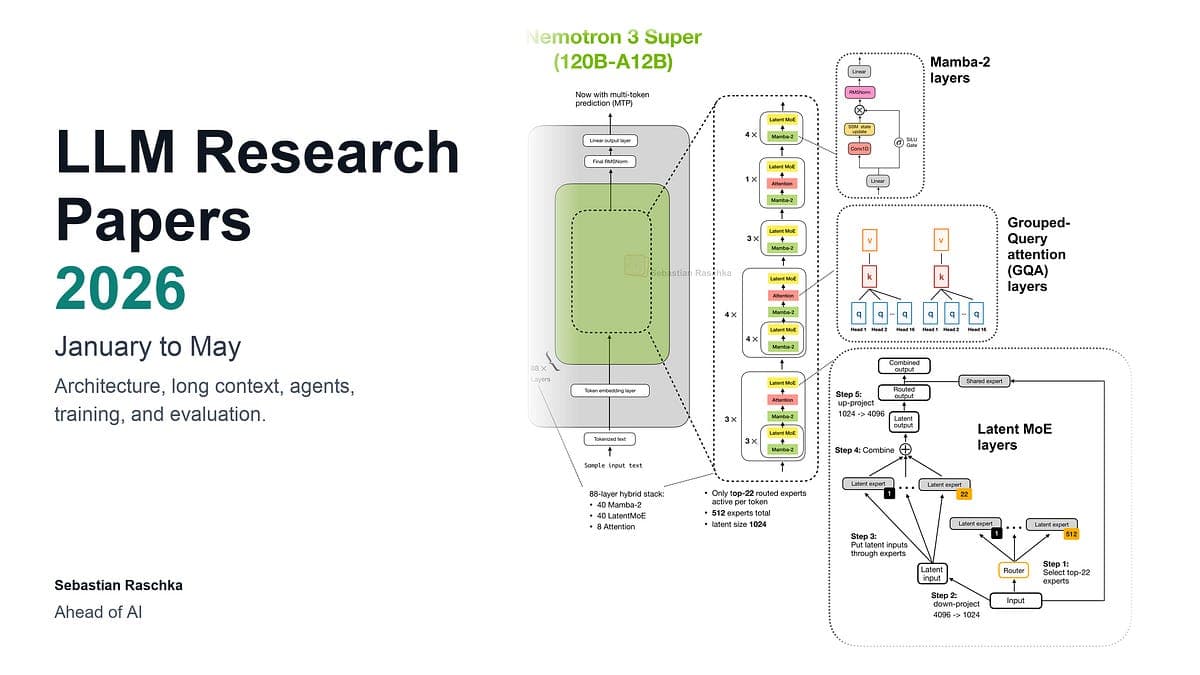
Les papiers IA qui comptent vraiment en 2026
Sebastian Raschka passe au crible 5 mois de recherche IA : voici les 10 catégories qui redessinent le secteur.

Groq lève 650M$ pour son cloud d'inférence après l'accord avec Nvidia
Groq passe de l'hardware à l'inférence cloud et demande à ses investisseurs de suivre.
Fireworks et Baseten deviennent décacornes : l'infra IA s'accélère
Deux startups d'infra IA franchissent les 10 milliards de valorisation en quelques mois. Le signal est clair : l'inférence explose.

Nemotron : générer du texte 6× plus vite sans renier l'autorégressif
NVIDIA lâche des modèles qui génèrent plusieurs tokens à la fois au lieu d'un seul : jusqu'à 6× plus rapide, et tu peux basculer entre 3 modes sans changer ton code.
KVBoost : accélère tes LLM de 5 à 48× sans GPU supplémentaire
Réutilise les caches d'un modèle LLM sur HuggingFace pour diviser par 5 le temps de réponse — et fais tourner du 32B sur 8 GB de RAM.

Nemotron, Laguna, vLLM 0.20 : la semaine qui change les infras
Trois lancements qui redéfinissent comment faire tourner l'IA en production : modèles omni, kernels plus rapides, orchestration d'agents.

Qwen3.6-27B : du code de niveau phare en 27B
Qwen sort un modèle 27B qui code comme son ancêtre 397B, 14× plus léger.