Tag
#nvidia
23 articles sur ce sujet.

AMD défie Nvidia avec son système Helios pour les géants de l'IA
AMD lance Helios, un système informatique capable de rivaliser avec Nvidia pour entraîner les plus gros modèles d'IA au monde.

NVIDIA sort Cosmos 3 Edge : l'IA robotique sur ton appareil
Un modèle de 4 milliards de paramètres qui apprend aux robots à comprendre leur environnement et agir en temps réel, directement sur ton matériel.

Le Japon bâtit son empire de l'IA physique avec Nvidia
Huang a scellé des alliances cruciales au Japon : une usine IA nationale, des robots, des puces maison.
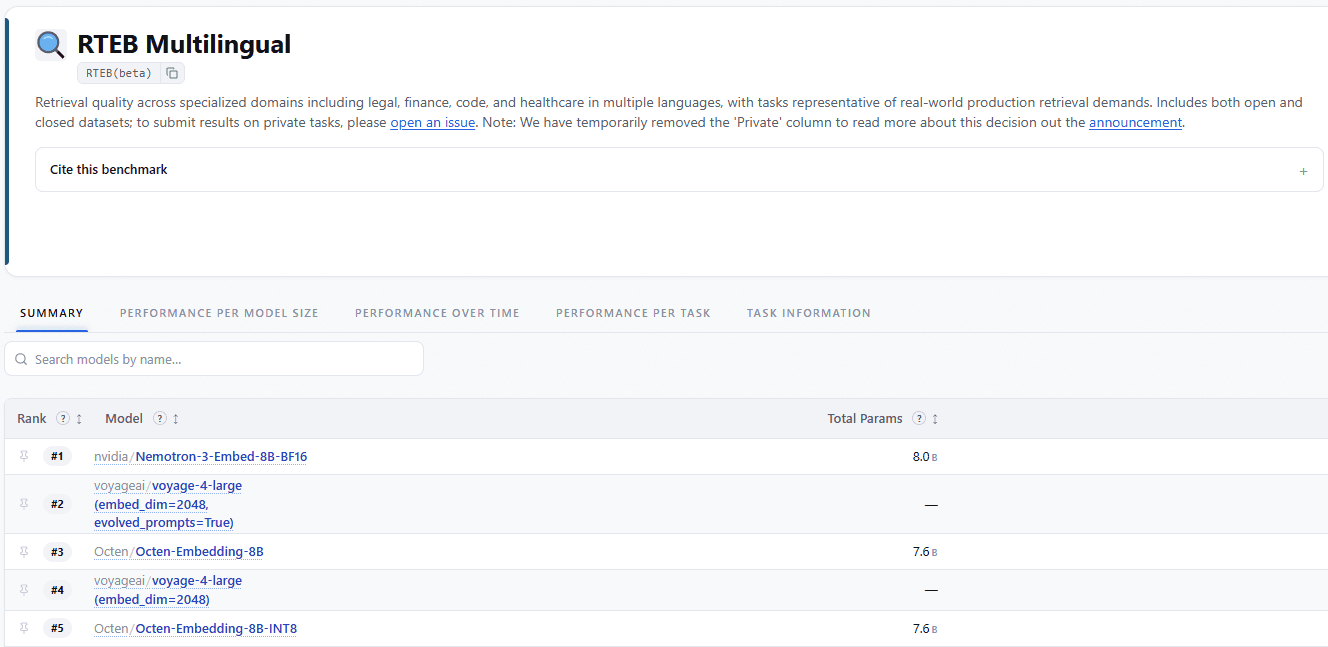
NVIDIA Nemotron 3 Embed : la recherche d'infos enfin fiable pour tes agents IA
Les agents IA perdent du temps à chercher les mauvaises infos. NVIDIA lâche un modèle d'embedding qui réduit ça de 27%.
Pourquoi les agents IA ont besoin de données ouvertes (et synthétiques)
Un agent IA qui ne sait pas gérer un appel API cassé n'est qu'un autocompléteur avec des outils.

Micron : pourquoi Wall Street la voit comme la prochaine Nvidia
Micron a brièvement dépassé Meta et Tesla en valeur boursière. La raison ? La pénurie mondiale de mémoire pour serveurs IA.

L'IA ouverte explose en mille modèles spécialisés
Les géants chinois ne dominent plus. Des centaines d'acteurs lancent maintenant leurs propres modèles, chacun optimisé pour un besoin précis.

OpenAI sort Jalapeño, son premier chip maison
OpenAI fabrique sa propre puce d'inférence avec Broadcom pour réduire sa dépendance à Nvidia.

Aive + Nvidia : les vidéos enfin compréhensibles par les IA
Les IA ne savaient pas lire les vidéos. Aive et Nvidia viennent de changer ça avec une plateforme qui transforme chaque vidéo en connaissance indexable.

H Company rejoint la coalition Nemotron de Nvidia
La startup parisienne H Company accède aux ressources partagées de Nvidia pour accélérer ses modèles IA autonomes.

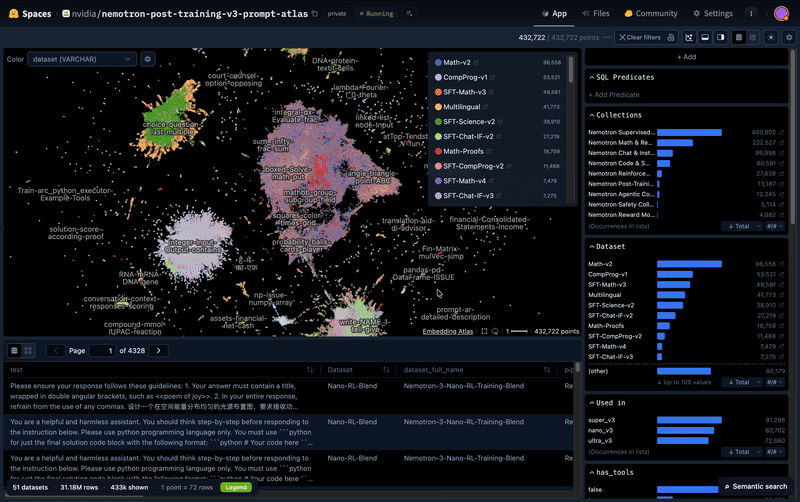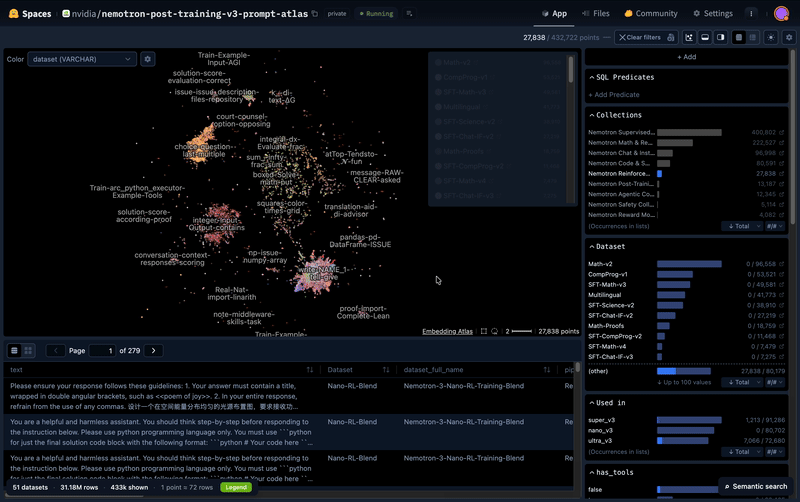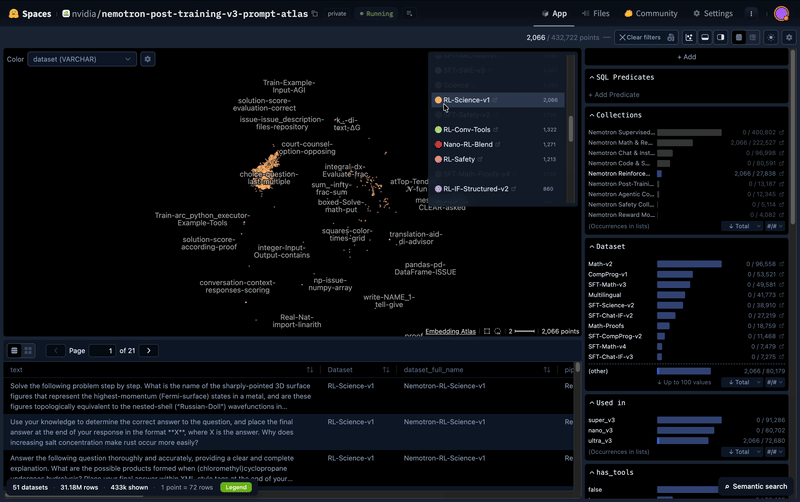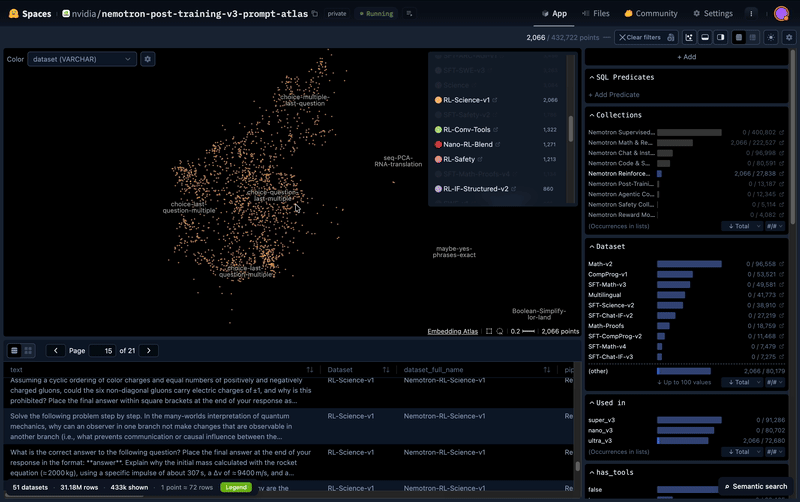
Comment NVIDIA crée de meilleures données pour ses IA
NVIDIA a découvert que générer 700 tâches d'apprentissage, c'est mieux que d'avaler 100 milliards de tokens bruts.

Nvidia + Unitree : le robot humanoïde made in China, cerveau américain
Nvidia et la startup chinoise Unitree créent ensemble le modèle de référence du robot humanoïde de demain : 6 pieds, 150 kg, et des mains qui font des tours de cartes.

Nvidia RTX Spark : enfin des vrais PC IA sous Windows
Nvidia lance des laptops qui font enfin ce que Microsoft promettait depuis 2 ans : faire tourner de vrais modèles d'IA en local.
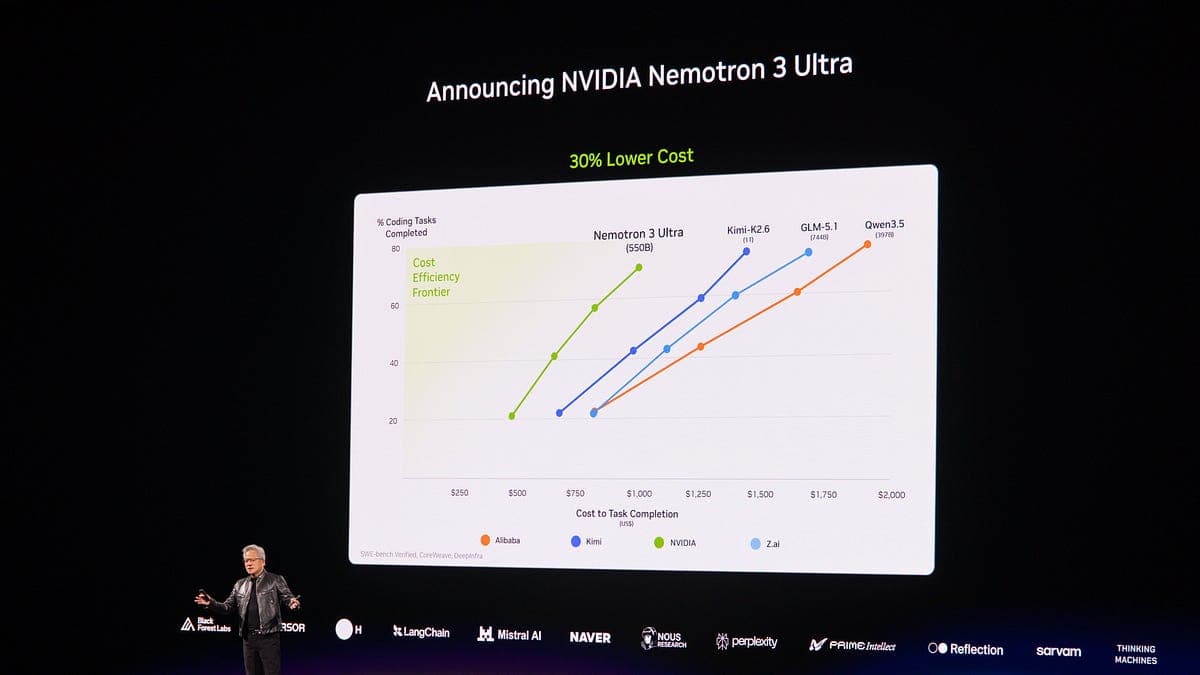
NVIDIA lâche trois bombes : Cosmos 3, Nemotron Ultra et RTX Spark
NVIDIA déverrouille trois modèles d'un coup : un géant du vidéo-to-text, un LLM ultra-rapide, et un PC surpuissant.

Cosmos 3 : le modèle IA qui comprend vraiment la physique
NVIDIA sort un modèle unique capable de générer des vidéos, raisonner sur la physique et contrôler des robots — tout en un.

Groq lève 650M$ pour son cloud d'inférence après l'accord avec Nvidia
Groq passe de l'hardware à l'inférence cloud et demande à ses investisseurs de suivre.
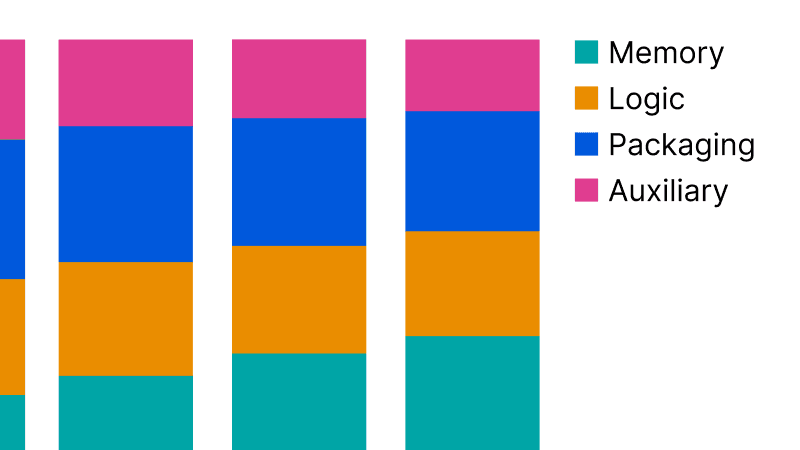
La mémoire dévore le budget des puces IA
En un an, la mémoire représente 63% du coût des puces IA — contre 52% avant. Nvidia, AMD et Google paient le prix.

Nemotron : générer du texte 6× plus vite sans renier l'autorégressif
NVIDIA lâche des modèles qui génèrent plusieurs tokens à la fois au lieu d'un seul : jusqu'à 6× plus rapide, et tu peux basculer entre 3 modes sans changer ton code.

Fine-tune Cosmos pour générer des vidéos de robots
NVIDIA te montre comment adapter son modèle vidéo géant à tes robots sans GPU coûteux.

Pourquoi Nvidia est devenue une entreprise logicielle
CUDA n'est pas un chip, c'est le fossé infranchissable qui protège Nvidia de tous ses concurrents.

Nvidia investit 40 milliards dans l'IA en 2026
Nvidia mise 40 milliards en capital sur l'IA en 2026 — dont 30 dans OpenAI seul.

Jensen Huang affirme l'IA crée des emplois, pas du chômage
Le PDG de Nvidia affirme que l'IA génère massivement des emplois, contrairement aux craintes des travailleurs.

NVIDIA Nemotron 3 Nano Omni : l'IA qui comprend texte, image, vidéo et audio
Un modèle open-source qui traite documents, vidéos et audio en natif, 9x plus rapide que ses concurrents.