Anthropic dépasse OpenAI : 47B$ de revenus et Claude Opus 4.8
Pourquoi ça compte pour toi
Pour la première fois, une entreprise IA challengers rattrape OpenAI sur les métriques qui comptent vraiment : chiffre d'affaires, valorisation, traction utilisateurs. Claude Opus 4.8 corrige les défauts d'Opus 4.7 et devient SOTA (état de l'art) sur les benchmarks qui décident des contrats clients. Si tu choisis tes outils IA, c'est le moment de retester Claude.
Ce qu'il faut retenir
- 1.Anthropic valorisée à 965B$ après dilution, après une levée de 65B$ (dont 15B$ des hyperscalers)
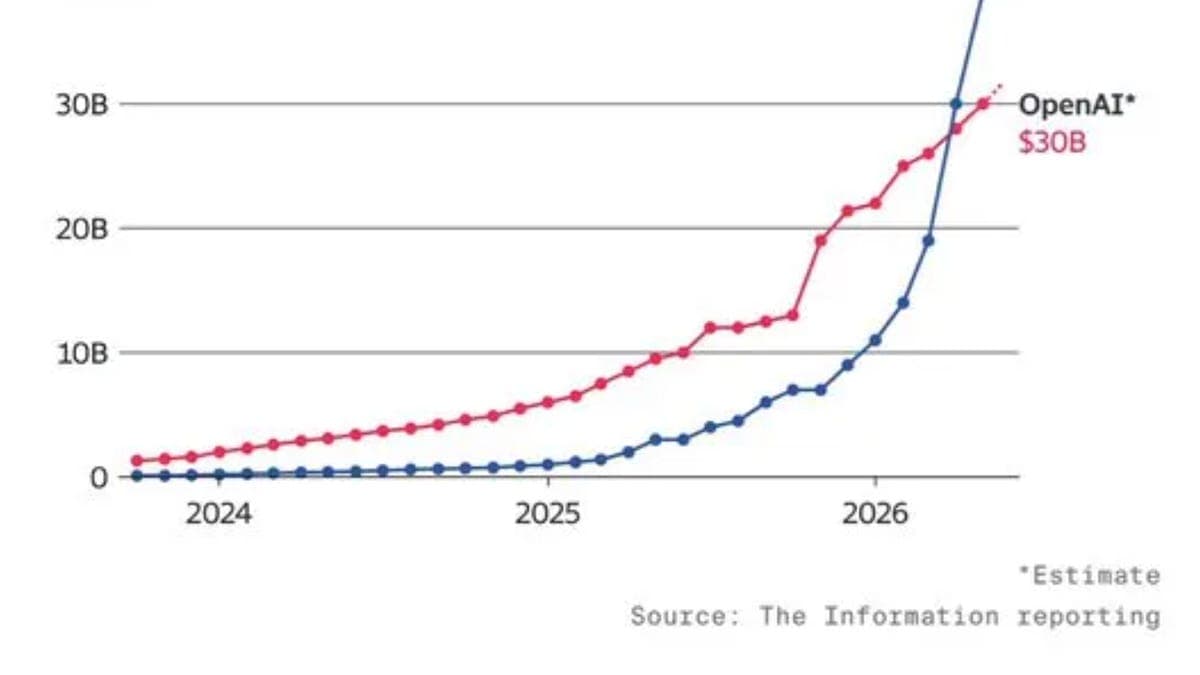
- 2.Revenus annualisés : 47B$ (contre 9B$ en décembre 2025, soit 5x en 5 mois)
- 3.Claude Opus 4.8 en tête sur presque tous les benchmarks économiquement pertinents
- 4.Anthropic désormais en tête sauf sur puissance de calcul et benchmarks non-code
Tu galères avec le jargon ?
Lis la version réécrite en mode débutant — toutes les idées, sans le jargon.
Pourquoi ce chiffre fait trembler la vallée
Anthropicn'a pas juste levé du cash : elle a validé une trajectoire commerciale exponentielle. Passer de 9 à 47 milliards de revenus en 5 mois n'est pas une anomalie statistique — c'est la preuve que les clients (pas les benchmarks) votent Claude.
Opus 4.8 : la correction qu'on attendait
Opus 4.7 avait déçu après son lancement. La communauté signalait des bugs, des limitations inattendues. Opus 4.8 les adresse frontalement.
Concrètement, ça veut dire :
- ▸Moins d'hallucinations sur des tâches précises
- ▸Meilleure cohérence sur les prompts longs
- ▸Performance maintenue, stabilité gagnée
Sur les benchmarks qui décident des contrats (code, math, instruction-following), Claude 4.8 place la barre plus haut que GPT-4o et Gemini 3.5 Flash.
Ce qui change pour toi
Si tu construis avec Claude : c'est le moment de tester 4.8 en environnement de validation avant de basculer. La version corrige des cas limites pénibles.
Si tu cherches un modèle pour un projet sérieux : Claude n'est plus l'alternative « au cas où ». C'est maintenant l'option de première classe.
Le vrai test ? Demande à ton équipe IA ce qu'elle utilise vraiment en production. Les réponses parlent plus fort que les tableaux de benchmark.
Et concrètement pour toi ?
Choisis ton profil — la lecture de l'article change selon qui tu es.
Pour toi, retiens que la compétition entre Anthropic et OpenAI s'accélère et que les deux deviennent interchangeables pour 90% des usages. Le vrai enjeu c'est qui maîtrise les hyperscalers (Google, Amazon, Microsoft) — c'est là que se gagne le marché, pas sur les benchmarks.
Essayer maintenant
Tester Claude Opus 4.8 gratuitement →Source
Pour aller plus loin
Cet article t'a donné envie d'approfondir ? Deux formations Noésis t'attendent :
Explorer les thèmes de cet article :