Tag
#benchmarks
9 articles sur ce sujet.

Les modèles ouverts chinois rattrapent enfin le terrain
Kimi K3, Qwen 3.8, Xi qui promet l'open source : les labs chinois accélèrent et posent des vraies questions aux géants US.

Pourquoi la vraie innovation en diffusion se fait en biologie, pas en LLM
Les chercheurs les plus doués abandonnent les LLM pour la découverte de médicaments. Voici pourquoi.

Ce qui ne peut pas s'apprendre : la vraie barrière de l'IA
Les modèles IA ne peuvent pas choisir ce qu'il faut construire. C'est là que gagnent les vrais entrepreneurs.

Les agents IA échouent massivement sur les vraies tâches
Trois nouveaux benchmarks le prouvent : même les meilleurs agents IA plafonnent à 2,6% de réussite sur des tâches réelles.

Comment NVIDIA crée de meilleures données pour ses IA
NVIDIA a découvert que générer 700 tâches d'apprentissage, c'est mieux que d'avaler 100 milliards de tokens bruts.
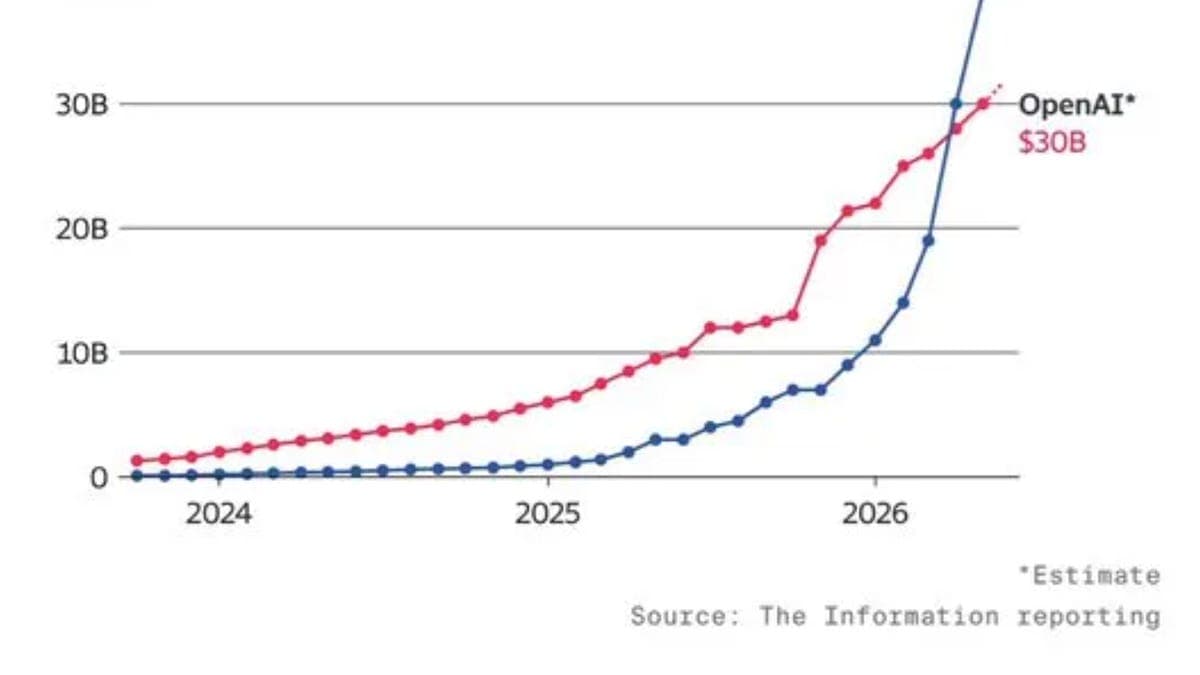
Anthropic dépasse OpenAI : 47B$ de revenus et Claude Opus 4.8
Anthropic vient de lever 65 milliards en Series H et affiche 47 milliards de revenus annualisés.

Les IA se trompent bien plus qu'on le croit (selon une fact-checkeuse)
Une fact-checkeuse professionnelle a testé ChatGPT, Claude et Gemini. Aucun n'a réussi à vérifier un seul fait.

Gemma 4, DeepSeek V4 : les modèles ouverts creusent l'écart avec l'Amérique
Les modèles ouverts chinois et indiens rattrapent, mais CAISI le confirme : l'écart avec la frontière américaine s'élargit.
Évaluer l'IA coûte désormais plus cher que l'entraîner
L'évaluation des modèles IA est devenue si chère qu'elle redéfinit qui peut faire de la recherche.